Building the World's Fastest AI Knowledge Base: How We Achieved Sub-100ms Retrieval

Introduction to knowledge base - and why latency matters
Every retrieval-augmented generation system makes an implicit promise: I will find you the right information, right now. The "right now" part is where most implementations quietly break down.
A knowledge base, at its core, is the memory layer of an AI system. It stores documents, indexes their meaning as vector embeddings, and retrieves the most relevant chunks when an agent or an LLM needs context to generate a grounded response. Without it, AI agents are limited to whatever fits inside their context window or whatever they absorbed during training. With it, they can reason over up-to-date, domain-specific information - company policies, product documentation, research papers, customer records - in real time.
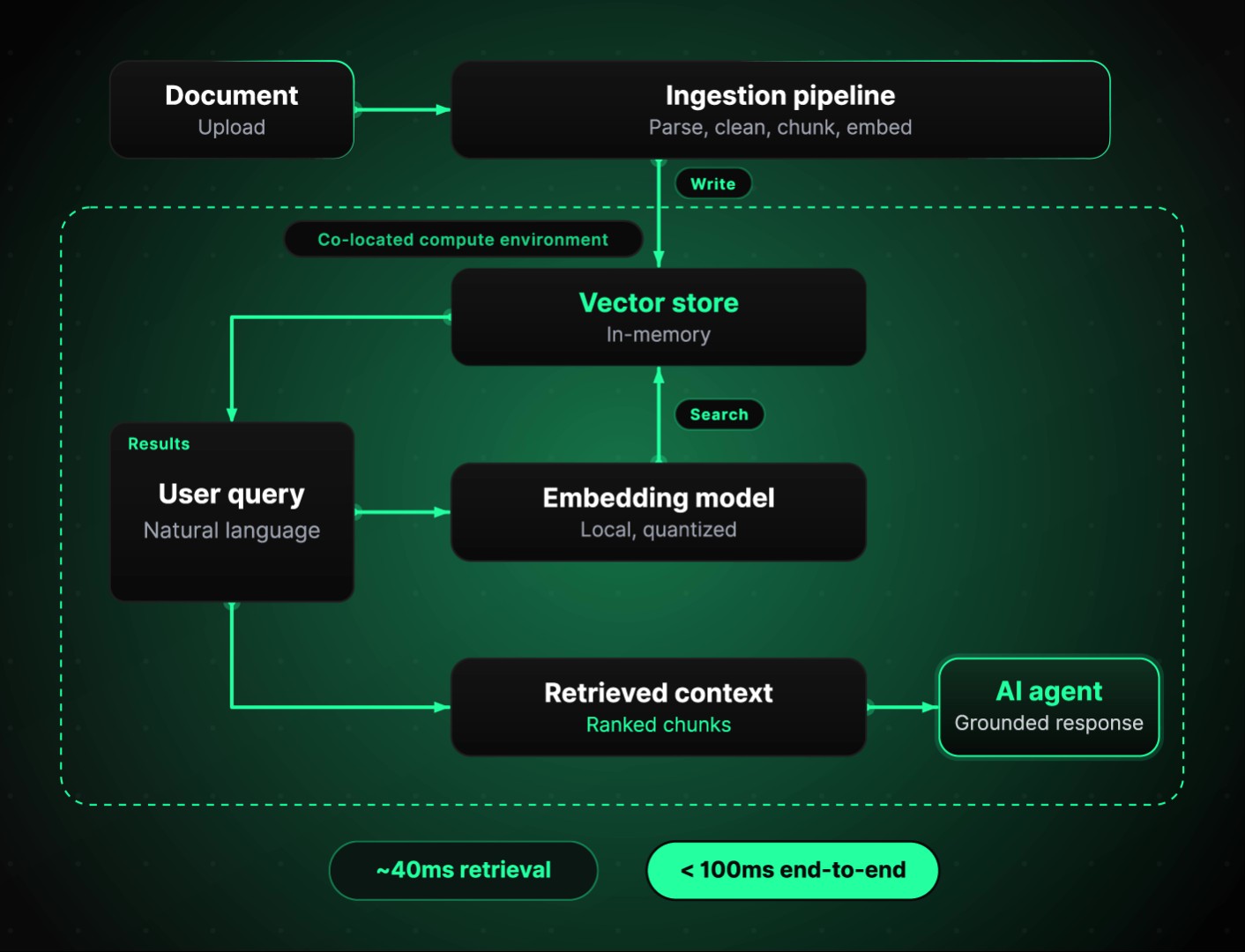
The architecture behind most knowledge bases follows a well-established pattern: documents are ingested, split into chunks, converted into vector embeddings, and stored in a vector database. At query time, the user's question is also converted into an embedding, and the database returns the most semantically similar chunks. These chunks are then fed into the LLM as context, enabling it to generate an answer that is both relevant and traceable to its source.
This is the promise of RAG. In theory, it is elegant. In practice, it has a problem.
The latency problem
For conventional search applications - a help desk, a document lookup tool - an extra few hundred milliseconds is tolerable. Users type a query, wait a moment, and scan the results. The interaction model has slack built into it.
But the moment you introduce a knowledge base into a real-time agent pipeline, that slack disappears entirely. Our platform at TruGen AI powers video-based agents that need to retrieve, reason over, and respond with grounded knowledge in the span of a single conversational turn. At that cadence, every millisecond of retrieval latency compounds. A 500ms round trip to the knowledge base doesn't just feel slow - it breaks the illusion of a responsive, intelligent agent. The user perceives hesitation. The conversation loses its rhythm.
Most production RAG pipelines today operate in the 300ms to 500ms range. For a batch workflow or a search bar, that is fine. For a real-time video agent that queries knowledge on every turn, it is a dealbreaker.
Where we started
We began where most teams begin. Hosted embedding APIs. A managed vector database. Standard HTTP REST endpoints stitching everything together. It was the architecture that every tutorial recommended and it worked - in the narrowest sense of the word.
Documents went in, Vectors came out. Queries returned results.
But the numbers told a different story, Embedding API calls introduced unpredictable network latency. The managed vector database added its own round-trip overhead. REST payloads were verbose. And because the agent engine and the knowledge retrieval layer lived in separate compute environments, every query paid a network transit tax on top of everything else.
End-to-end, a single query-to-retrieval cycle regularly hit around 500ms. For a system designed to answer on every conversational turn, in real time, that was unacceptable.
We needed to rethink the architecture from the ground up.
How we solved latency with our knowledge base
What followed was not a single optimization but a systematic re-engineering of every layer of the stack - from how we generate embeddings, to how we store and query vectors, to how bytes move between services. Four components, each contributing a measurable reduction in latency, together producing a result that none of them could have achieved alone.
Component 1: A Quantized embedding model
Off-the-shelf embedding models presented a familiar trade-off: accuracy or speed, pick one. We evaluated a range of models through extensive inference benchmarking and identified a candidate that consistently produced reliable, semantically rich embeddings. The problem was that its model size and inference time were too high for production use in a latency-sensitive pipeline.
Rather than accept that trade-off, we explored quantization techniques and iterative model pruning. Through careful experimentation, we arrived at a configuration that delivers sub 40ms embedding latency on CPU, without meaningful degradation in embedding quality. We run this model locally using FastEmbed, which eliminates the network overhead of hosted embedding APIs entirely. No external API call, no round-trip variance, no cold starts - just a deterministic, fast embedding step that lives inside our own infrastructure.
To squeeze additional efficiency out of this layer, we introduced two further optimizations. First, an LRU cache ensures that repeated queries - which are surprisingly common in agent-driven workflows - reuse previously computed embeddings rather than recalculating them. Second, embedding generation runs on a dedicated thread, keeping the main server loop responsive while vectors are being computed.
Component 2: An In-memory vector database
We evaluated several high-performance vector databases and landed on Qdrant. Its combination of reliability, query performance, and operational simplicity made it the clear choice for our retrieval layer.
Critically, we chose to self-host Qdrant and run it entirely in memory. Disk-backed vector search introduces I/O latency that, while small in absolute terms, adds up quickly under load. With the full index resident in memory, Qdrant can scan and rank thousands of vectors in a few milliseconds using cosine similarity - no disk seeks, no page faults, no surprises.
We also made a deliberate architectural decision to keep the vector database focused exclusively on storage and retrieval. All heavy processing - document parsing, text cleaning, embedding generation, batching - happens upstream in the ingestion pipeline. The Qdrant server never has to compete for resources between write-heavy ingestion workloads and latency-sensitive search queries.
Component 3: gRPC with binary protobuf transport
This component required the most iteration, and ultimately delivered one of the largest single improvements.
We began with a standard HTTP REST API - the obvious starting point. JSON payloads, synchronous request-response cycles, a new TCP handshake for every query. Latency was immediately problematic, The HTTP handshake overhead alone was a non-starter at the response times we were targeting.
We moved to WebSockets, which eliminated the per-request handshake overhead and brought us down to roughly 500-600ms round-trip time. Adding packet-level compression reduced this further to 400-500ms. Meaningful progress, but still far from our goal.
The final iteration adopted gRPC with compression. This combination proved to be the decisive factor. gRPC's binary framing, HTTP/2 multiplexing, and compressed Protobuf payloads brought our transport layer latency down to the 100-150ms range. The payloads themselves are dramatically smaller than their JSON equivalents - a vector search request that might be several kilobytes as JSON compresses to a few hundred bytes as a Protobuf message.
We now use gRPC for all communication between the application layer and Qdrant, both for ingestion writes and search queries.
Component 4: Compute and knowledge colocation
The final lever was architectural rather than technical, and in some ways it was the most obvious optimization we could have made.
In our initial setup, the agent engine and the knowledge retrieval infrastructure ran in separate compute environments. Every query paid a network transit penalty - data center to data center, or at minimum, availability zone to availability zone. No amount of protocol optimization can eliminate the speed of light.
By co-locating both systems within the same compute environment, we cut the remaining transport latency roughly in half. The query never leaves the local network. The round trip from agent to knowledge base and back becomes a matter of microseconds of network overhead rather than milliseconds.
This single change pushed our average end-to-end query-to-retrieval time comfortably under 100ms.
Implementation challenges
Architecture diagrams are clean. Production systems are not. While the high-level design gave us the performance characteristics we needed, getting there involved solving a series of practical engineering challenges that no whiteboard sketch prepares you for.
Memory pressure during document ingestion
One of the first problems we hit was that document ingestion consumed too much RAM when everything ran on a single system. Processing an entire document at once - parsing, cleaning, embedding, and indexing - created memory spikes that destabilized the Qdrant server and degraded search performance for active users.
The solution was to separate ingestion from retrieval entirely. We moved all document processing into AWS Lambda functions, triggered by SQS messages when a file lands in S3. The Lambda downloads the document and processes it page by page, grouping pages into batches of ten to keep memory consumption predictable. This batching strategy was the result of trial and error - too few pages per batch meant excessive Lambda invocations and overhead; too many brought back the memory pressure we were trying to escape.
By isolating ingestion in Lambda, the Qdrant server is free to focus entirely on what it does best: storing vectors and answering queries. The two workloads scale independently, and a burst of document uploads no longer starves the query path.
Concurrency and lock contention
Since Qdrant runs locally with a single worker in our setup, concurrent operations introduced a real risk of conflict. A write from the ingestion pipeline and a search query arriving at the same moment could produce errors - particularly when the storage folder was being accessed simultaneously.
We addressed this with a PriorityLock mechanism using a dedicated lock. Search requests are treated as high priority, ensuring that write operations yield to active searches. This prevents the subtle, intermittent latency spikes that are notoriously difficult to diagnose in production.
Text quality and embedding noise
A less obvious but equally impactful challenge was the quality of text being fed into the embedding model. Raw document text is noisy - full of unnecessary whitespace, hyperlinks, formatting artifacts, and layout remnants that carry no semantic meaning. Embedding models do not distinguish between signal and noise; they encode whatever they receive.
We introduced a text cleaning step before embedding: stripping whitespace, removing URLs, and normalizing formatting. The effect on retrieval quality was immediate and significant. Cleaner input produces tighter, more semantically focused embeddings, which in turn produce more relevant search results.
Chunking granularity
Our initial approach embedded entire pages, which meant each vector represented a broad, often incoherent mix of topics. A single page might discuss three distinct concepts, and the resulting embedding would be a blurred average of all three - useful for none of them.
We experimented with smaller, more focused chunks - segments of text that each represent a single idea or section. This dramatically improved the precision of vector similarity search. A query about a specific concept now matches against a vector that represents that concept cleanly, rather than a vector that represents an entire page where the concept happens to appear.
Getting the chunk size right required iteration. Too small, and the chunks lose context - a sentence in isolation can be ambiguous. Too large, and we are back to the blurred-average problem. We settled on a granularity that preserves enough surrounding context to be meaningful while keeping each vector tightly scoped to a single topic.
Retrieval tuning
Returning fast results is not the same as returning good results. Early on, our search queries returned a high volume of matches, but many of them were only loosely related to the query. The system was optimized for recall at the expense of precision.
We tuned the retrieval parameters to prioritize high-relevance results: adjusting the top-K value, applying similarity score thresholds to filter out low-confidence matches, and enriching the metadata stored alongside each vector - page numbers, chunk identifiers, source filenames - so that downstream systems can trace every result back to its exact location in the original document.
The result is a retrieval layer that is both precise and predictable: fewer results, but each one meaningfully relevant and fully traceable.
The results
The cumulative effect of these four optimizations brought our RAG pipeline to a point where knowledge retrieval introduces no perceptible lag in the user experience.
On average, our search and retrieval pipeline operates in the 40ms range when working with large document collections. End-to-end, from query submission to structured results delivered back to the agent, we consistently land under 100ms.
To our knowledge, this makes TruGen AI's knowledge base the fastest production RAG retrieval system in the world. We have not encountered another system - commercial or open-source - that achieves comparable end-to-end latency at this level of retrieval quality. Most production RAG pipelines operate in the 300ms2s range; we operate in the range where latency becomes imperceptible.
| Component | Before | After |
| Embedding generation | Hosted API (variable, network-bound) | Local quantized model (sub-40ms, on CPU) |
| Vector database | Managed, disk-backed | Self-hosted Qdrant, fully in-memory |
| Transport protocol | REST/JSON | gRPC/Protobuf with compression |
| Compute topology | Distributed across environments | Agent and KB co-located |
| End-to-end retrieval | ~500ms | < 100ms |
Our agents can now query the knowledge base on every conversational turn, in real time, with no practical cost to responsiveness. This unlocks a qualitatively different class of agent behaviour: one that is always grounded, always current, and always fast.