Building Huma 2: A Real-Time Avatar with Sub-500ms Latency
How we designed a full speech-to-animation pipeline — and what we learned pushing Gaussian-based lip sync to its limits.

The Challenge
Building an interactive avatar that sees, listens, and responds like a human is a deceptively hard problem. The technical hurdles aren't just accuracy — they're speed. A beautiful avatar that lags by two seconds feels broken. Our target: complete the entire pipeline in under 500ms.
Two variables dominate every design decision: latency and quality. We found that smaller, faster models were the key to threading this needle without sacrificing the realism that makes an avatar believable.
The Pipeline
A real-time avatar isn't a single model — it's an orchestrated chain of specialized systems working in parallel.
Here's the architecture we settled on

Each stage adds latency, Our job was to shrink every link in this chain — especially the lip sync model, which sits at the end and directly determines the perceived quality of the avatar.
Choosing a Lip Sync Architecture
Lip sync is where realism lives or dies. We evaluated three broad families of architectures before committing to Gaussian Splatting, Its explicit scene representation makes it fast to render and straightforward to deform — exactly what we needed for a real-time, audio-driven animation system.
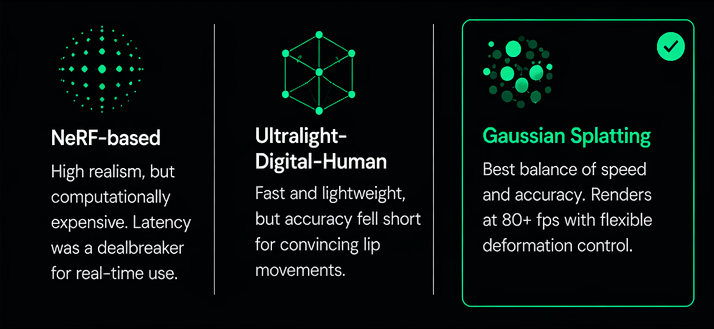
Training requires only 2–3 minutes of pre-recorded video in a controlled setting. This keeps data collection practical and accessible, without compromising model quality.
Huma 1: The Foundation
Our first architecture, Huma 1, established the core two-step Gaussian pipeline
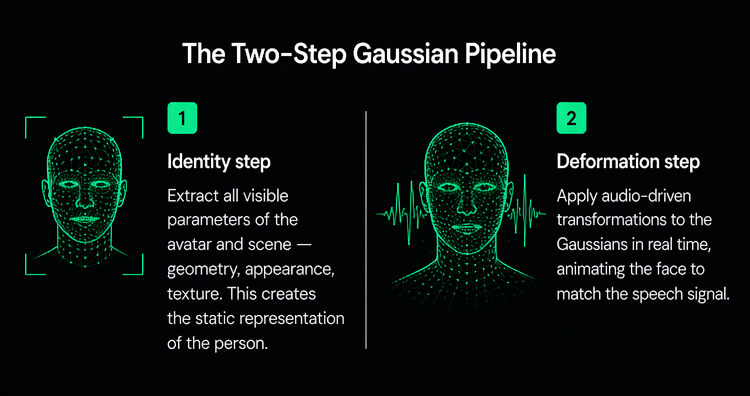
Huma 1 also introduced our two-phase runtime model, which became the foundation for all future work

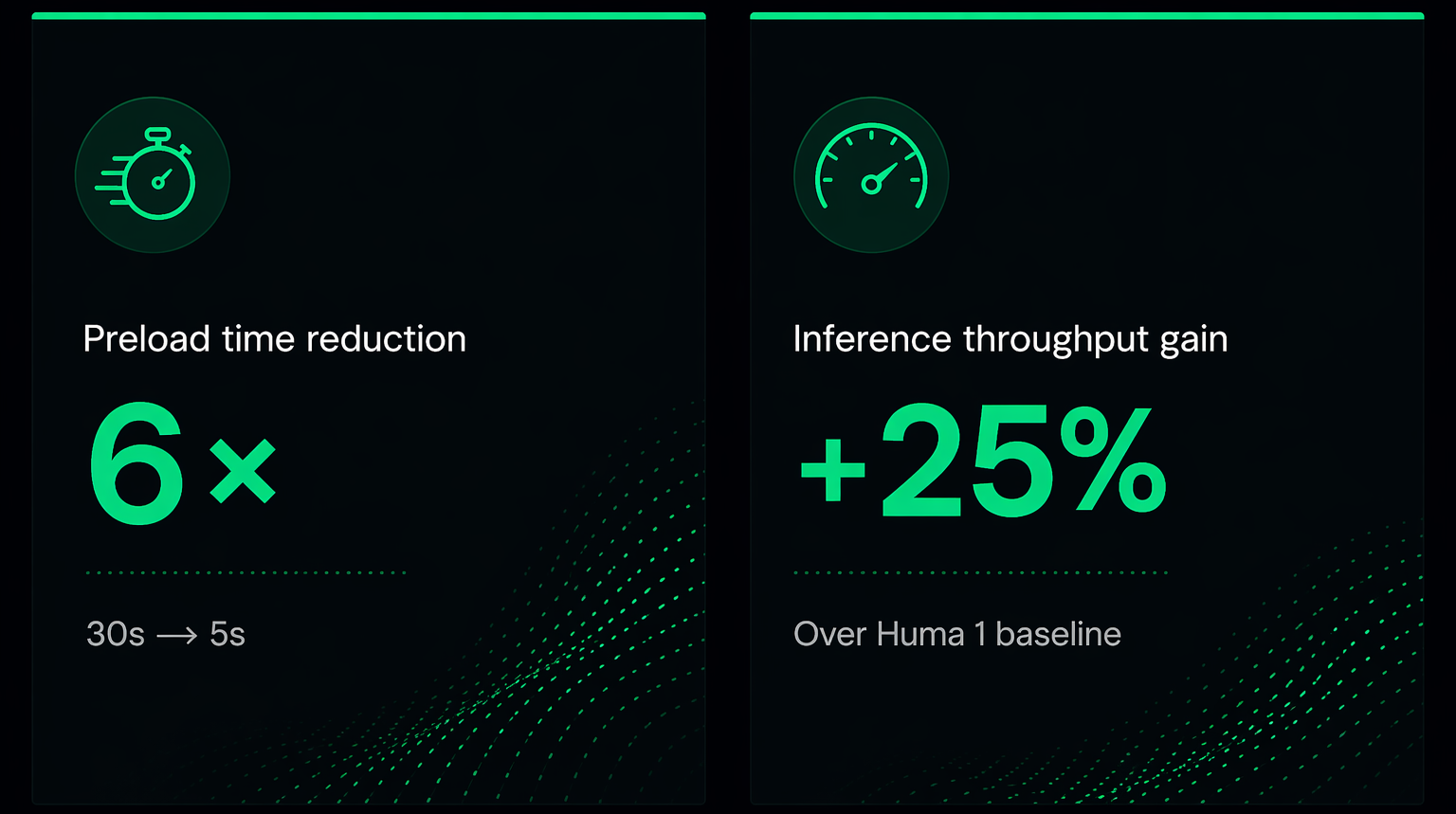
The preloading cost was significant — 20 to 30 seconds on a single GPU with 8 CPU cores. Acceptable for a prototype, but clearly a problem to solve for production deployments.
Huma 2: Rethinking Every Bottleneck
Huma 2 is the result of systematically attacking every source of latency in Huma 1 — models, data loading, pre-processing — without sacrificing accuracy. The changes touch every layer of the system.
Smaller models, bigger impact
We redesigned our internal models to be significantly smaller than their Huma 1 counterparts. Fewer parameters means faster inference, and the accuracy trade-off turned out to be negligible — we stayed within acceptable quality bounds while gaining substantial speed.
Minimized data loading and pre-processing
The original pipeline had pre-processing stages that loaded more data than necessary and ran heavier operations than required. In Huma 2, we audited every step, replacing or eliminating pre-processing models that were overdoing it for our specific use case. The result is a leaner boot sequence with no loss in output quality.
Smoother audio encoding
A notable improvement in Huma 2 is robustness to variation in training data. The audio encoder now operates more smoothly across different recording conditions, making the model less sensitive to edge cases in the input data. This wasn't just a quality win — it simplified our data collection requirements significantly.

Key Takeaways
After two generations of architecture, a few principles have proven durable
Gaussian Splatting offers a uniquely practical trade off for avatar rendering: fast enough for real-time use, flexible enough for audio-driven deformation, and trainable from short video clips.
Splitting runtime into a preloading phase and an inference phase is a powerful design pattern. Front-loading work that doesn't change between sessions is a reliable way to minimize perceived latency.
Smaller models don't automatically mean worse models. Careful architecture design and targeted reduction of pre-processing overhead can produce a faster, more robust system with comparable output quality.